
Wenn Sie den Bereich "LDV-Orgs" erreichen, gilt es einige Grundsatzregeln zu befolgen, damit ein sinnvolles und performantes arbeiten möglich ist.
Bei großen Datenimports und -migrationen wird oftmals die Frage gestellt, wie viele Datensätze in Salesforce überhaupt geladen bzw. verarbeitet werden können? Die Antwort mag viele überraschen: das einzige Limit ist der Speicherplatz ("Data Storage") der Salesforce Org. Wenn genug Data Storage zur Verfügung steht, können weit mehr als 10 Millionen Datensätze gespeichert werden. Es gibt einige Kunden, die fast an die Milliarden-Grenze herankommen. Hier sprechen wir im Allgemeinen von Large Data Volumes ("LDV“ oder "LDV-Orgs").
Die Frage lautet vielmehr "wie können wir effizient mit den Daten arbeiten“ statt "wie viele Daten können wir speichern"? Wenn Sie den Bereich "LDV-Orgs" erreichen, gilt es einige Grundsatzregeln zu befolgen, damit ein sinnvolles und performantes arbeiten möglich ist. In dem folgenden Blogartikel gebe ich Ihnen einige Handlungsempfehlungen an die Hand.
1. Überprüfen Sie Ihr Datenmodell
Das Datenmodell in Salesforce resultiert hauptsächlich aus der Abbildung der einzelnen Geschäftsanforderungen ("Business Requirments"). In dem Bereich der "LDV-Orgs" sollten jedoch weitere architektonische Anpassungen, sprich Optimierungen vorgenommen werden.
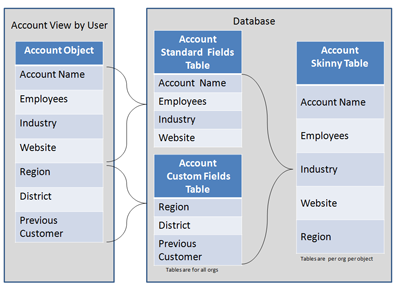
Skinny Tables
Oftmals besitzen Objekte sehr viele (Custom) Felder. Dies führt bei "LDV-Orgs" zu langsamen Seitenaufrufen, der Darstellung von List Views oder Reportings. Sofern eine Reduzierung der Anzahl von Feldern nicht möglich ist, können die sogenannten "Skinny Tables" (Aktivierung durch Salesforce Support) eine gute Lösung sein. Felder, etwa für Reporting, können eingegrenzt werden, wodurch eine schnellere Performance erzielt wird. Mehr zu Skinny Tables finden Sie hier.
Indexing
Eine weitere Möglichkeit, um die Performance bei "LDV-Orgs" zu optimieren, bietet die Indexierung von bestimmten Feldern. Salesforce besitzt einen SOQL Query Optimizer mit welchen indexierte Felder schneller verarbeitet werden. Einige Felder sind per Standard bereits indexiert (z. B. ID oder Names-Felder), Custom Felder können zusätzlich indexiert werden. Mehr zu diesem Thema finden Sie hier.
Datensatzinhaberschaft
Wie schon in meinem vorherigen Blogartikel beschrieben, basiert das Datenmodell in Salesforce auf dem Konzept der Dateninhaberschaft ("Data Ownership"). Um eine gute Performance zu erhalten, sollten die Datensätze zwischen den Usern möglichst gleichmäßig verteilt werden. Vermeiden Sie einen einzelnen User als Inhaber für einen Großteil der Datensätze. Wenn trotzdem ein User sehr viele Datensätze innehat , sollte dieser User außerhalb der Rollenhierarchie oder an der Spitze der Rollenhierarchie angesiedelt sein. Mehr zu diesem Thema finden Sie hier.
Parent – Child Relationships
Eine Vielzahl von "Child-Records" erschwert ein effektives Arbeiten in Salesforce. Sie sollten daher nicht mehr als 10.000 Child Records pro Parent Record haben. In einem "B2C" Geschäftsmodell sollte die "Person Account" Funktion aktiviert werden, bevor die "B2C" Kontakt unter einem "Dummy" Account gehängt wird. Mehr zu diesem Thema finden Sie hier.
2. Schlanke Settings
Wenn "LDV-Orgs" in Salesforce importiert werden, empfiehlt es sich, eine möglichst "schlanke" Konfiguration einzustellen:
OWDs
Vor dem Datenimport von großen Datenmengen raten wir Ihnen die OWDs für die Objekte "Public Read/Write" zu stellen. Bei einer restriktiveren Einstellung wird andernfalls das Sharing – bei einem Insert – neu berechnet. Nach dem Datenimport können die OWDs wieder auf die ursprüngliche Einstellung geändert werden.
Relationships
Je mehr Beziehungen geladen werden, desto langsamer wird der Datemimport. Ebenso wichtig ist die Reihenfolge der zu ladenden Objektdatensätze: Laden Sie zuerst die "Parents", damit man den "Child“ Datensätzen einen Bezug zuordnen kann. Ein Import der Objektbeziehungen (nur bei Lookup-Relationships) kann auch nach dem initialen Datenload erfolgen, um den Datenload schneller durchführen zu können.
Sharing
Um die Sharing Berechnungen während des Uploads zu unterdrücken, kann die Einstellung Defer Sharing Calculations durch den Salesforce Support aktiviert werden.
Automations
Um einen schnelleren Import zu gewährleisten, überprüfen und deaktivieren Sie nach Möglichkeit Automations wie Workflows, Prozesse, Validierungsregeln oder Trigger für den Datenload. Einer besonderen Prüfung bedürfen hierbei alle E-Mail Benachrichtigungen, um einen ungewünschten Versand von E-Mails, während des Imports, zu vermeiden. Nach dem Import vergessen sie nicht wieder alle Automatisierungen zu aktivieren.
3. Reihenfolge bei LDV Uploads
Wie bereits erwähnt, ist es entscheidend, spezielle Abfolgen beim Dataload zu befolgen. Beispielsweise müssen erst alle Parent-Datensätze geladen werden, bevor die Child-Datensätze verknüpft werden können.
- Legen Sie zuerst die Rollen- bzw. Regionenhierarchie an. Anschließend können Sie User laden, Rollenhierarchien zuordnen und die Profile der User überprüfen.
- Prüfen Sie – vor dem Upload – die Quelldaten auf Konsistenz. Erfüllen die Daten die notwendige Voraussetzung (z. B. um in Felder mit bestehenden Validierungsregeln oder Datumsformat geladen zu werden)?
- Bestimmen und testen Sie die Batch Sizes für den Upload. Bei der Verwendung von Bulk API oder SOAP API ist es ratsam, die größtmögliche Batchgröße einzustellen. Mehr zu diesem Thema finden Sie hier.
- Laden Sie zuerst die Parent Records, bevor die IDs für die Beziehung der Child Records extrahieren.
- Sortieren Sie die Upload Daten nach der ParentIDs, damit ein Upload im Parallelmodus kein Record-Locking Fehler provoziert. Im Bulk API Parallelmodus können bis zu 1 Millionen Datensätze in ca. 6 Minuten geladen werden. Werfen Sie einen Blick auf ein Demovideo.
- Für einen schnelleren Upload wählen Sie die "Insert“ Operation, denn ein "Upsert" ist immer langsamer als ein "Insert" oder "Update" Operation.
- Für jeden Datenimport gilt vorab, den Import in der (Full) Sandbox zu testen.
Fazit
In Salesforce können problemlos große Datenmengen gespeichert und verarbeitet werden. Um ein performantes Arbeiten mit geringen Antwortzeiten zu erreichen, sollten gerade im Bereich von LDV-Orgs einige Grundsätze und "Best Practises" befolgt werden. Achten Sie möglichst auf eine gleiche Verteilung der Datensätze ("Record-Ownership") und vermeiden Sie eine hohe Anzahl (über 10.000) von Child-Datensätze. Über Indexierung oder Skinny Tables gibt es zusätzliche Möglichkeiten, die Antwortzeiten in Salesforce zu reduzieren.